OpenAI Cuts GPT-4.1 Prices to Stay Ahead in the AI Race
New models, lower costs — OpenAI is moving fast to stay competitive. In a market flooded with emerging AI startups and aggressive pricing from rivals like Anthropic and Mistral, OpenAI is making a bold move. The company has officially announced significant price reductions for its latest generation of models, including GPT-4.1 and GPT-4.1 Mini.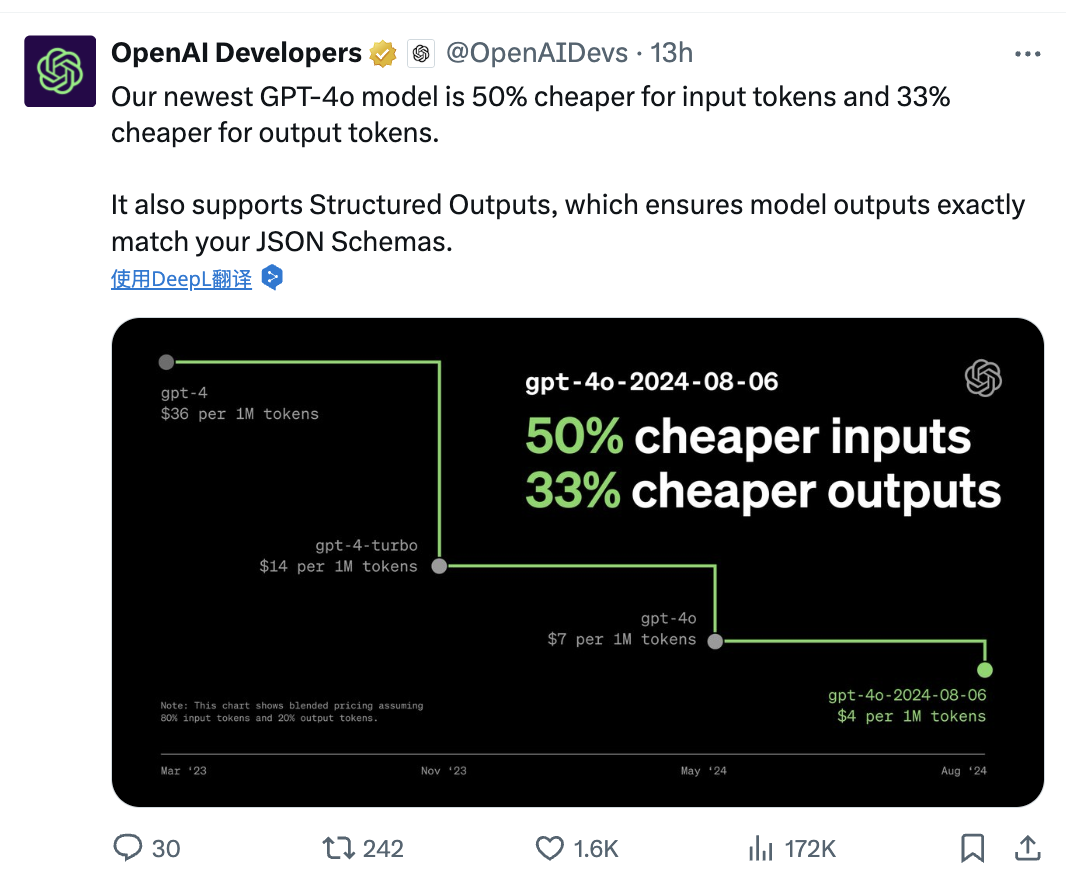
Introducing Flex Processing: 50% Off for Non-Urgent Tasks
OpenAI has also introduced Flex Processing, a beta feature that offers a 50% discount on API costs for the o3 and o4-mini models. This option is ideal for non-urgent tasks, as it trades off processing speed for cost savings. Pricing details:- o3 model: $5 per million input tokens (down from $10), $20 per million output tokens (down from $40)
- o4-mini model: $0.55 per million input tokens (down from $1.10), $2.20 per million output tokens (down from $4.40)

service_tier parameter to "flex" in their API requests, users can access these discounted rates.
It’s important to note that Flex Processing is currently in beta and may experience slower response times or occasional resource unavailability. Additionally, access to the o3 model under Flex Processing may require identity verification for users in lower usage tiers.